Olá, tenho uma dúvida sobre datas novamente kkk.
No meu TCC da curso R de faxina de dados, falta uma última coluna de datas somente para padronizar:
Estou importando dados de um pdf de óbitos por covid da prefeitura da minha cidade: https://covid19.pjf.mg.gov.br/arquivos/obitos_covid19_jf.pdf
O PDF separei em tabelas aqui:
No campo das DATAS, temos vários padrões:
Em números, temos “dd/mm/yy”, “dd/mm/yyyy”, “dd/mm”, “d/mm”, “dd/m” e “ddmm”.
Já lidei com os casos de número por extenso.
A meta é passar tudo para yyyy-mm-dd como objeto de data.
Para lidar com as linhas cujas datas que não tem meses ou anos, como a base é atualizada por dia,
a linha de cima provavelmente é o mesmo mês e ano do registro. Nesse caso, pensei fazer um tidyr::fill(direction =“down”) para lidar com as faltas.
Isso até que poderia dar certo para datas no mesmo ano, mas quando ficamos com datas perto da virada de 2020 para 2021, isso pode dar bastante erro.
A base é ordenada por cada dia, o que representa uma data de notificação.
Agora, a coluna data_obito que precisa ser padronizado é a data do obito efetivo, nao que ele foi notificado.
Isso funciona bem nesse caso, quando ainda estamos somente em 2020…
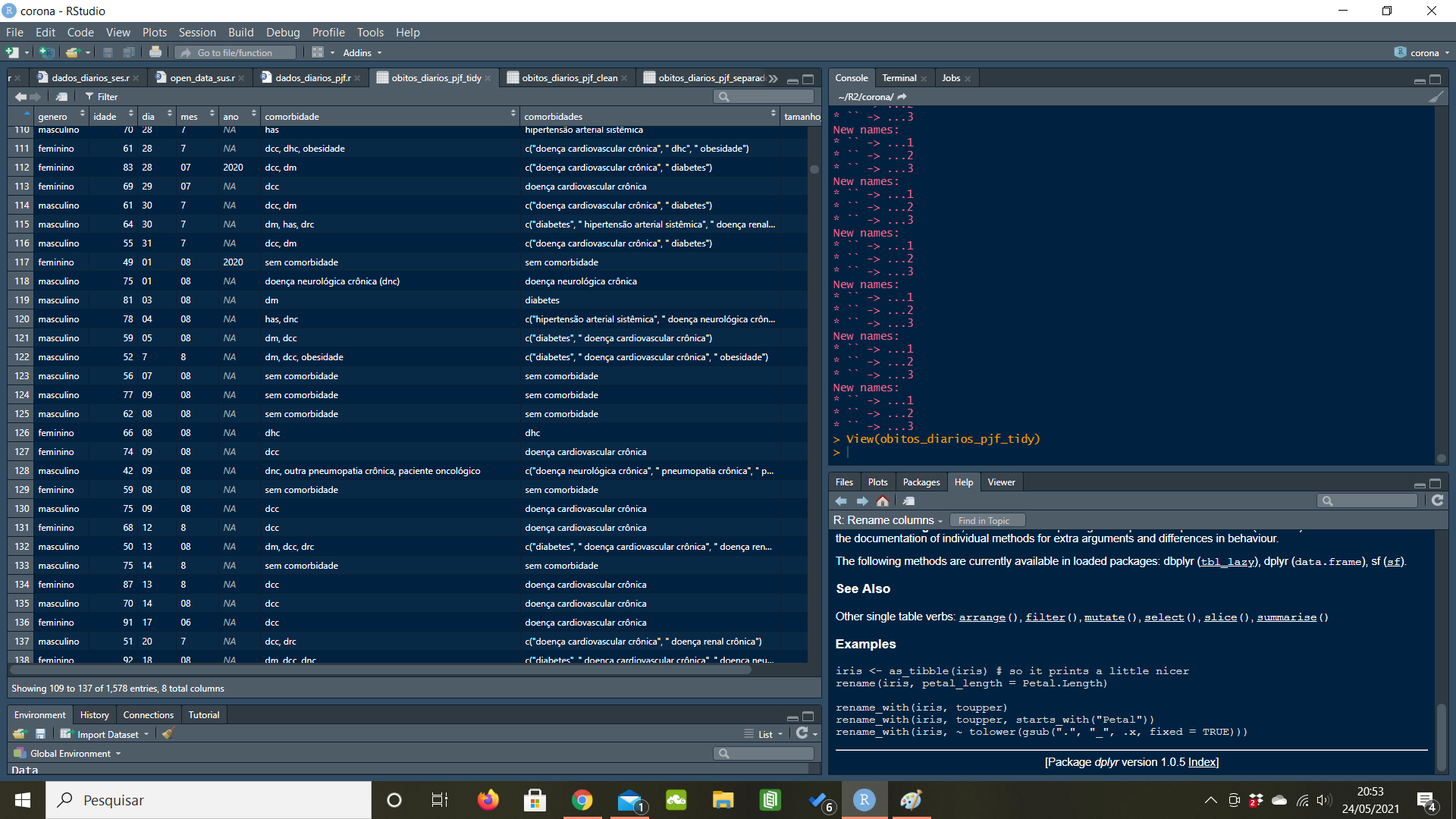
Mas quando chegamos na virada do ano, o problema aumenta:
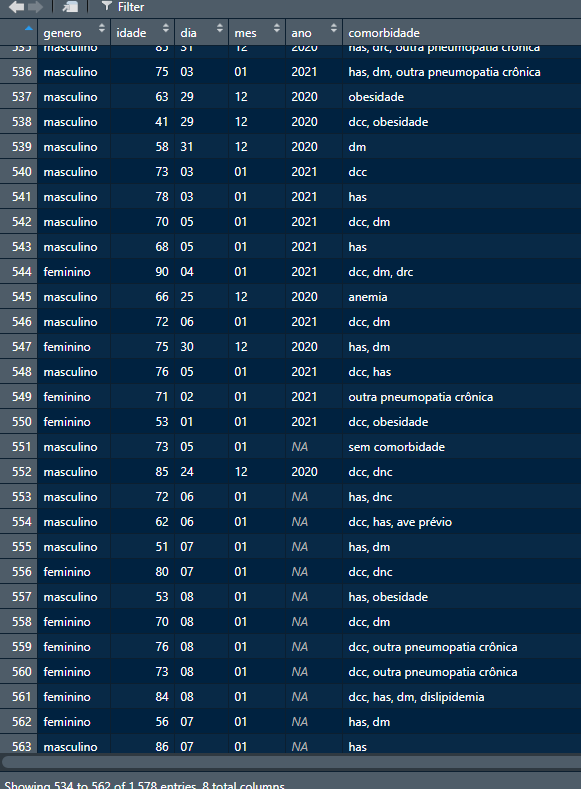
nesse caso, é a base vem 27/12/2020, 31/12/2020, vira para 01/01/2021, e de repente tem um 28/12/2020. o direction= “down” aqui agora vai gerar uma série 01/01/2020, 07/01/2020, quando nem tinha começado a pandemia.
Como resolver essa questão? Alguma forma de resolver isso por área do data frame? na mão quando estivermos perto da virada? ou é melhor deixar um NA mesmo?
 ótima escolha para o TCC de faxina.
ótima escolha para o TCC de faxina.