Olá, estou escrevendo o meu TCC sobre o curso Faxina de Dados e tenho uma dúvida sobre como tirar processos manuais e melhorar a reprodutibilidade.
A faxina está pronta na verdade há mais de 10 dias, mas me neguei a entregar em word, pdf ou comentado no código, e me desafiei a fazer o Rmarkdown por não ter feito antes.
Mas vamos lá, a base que faxinei está aqui na prefeitura de Juiz de Fora, nesse pdf, que é atualizado diariamente .
é um pdf digital que li com pdf_tools::read_pdf(minha pasta/obitos_covid19_jf.pdf), mas, para aumentar a reprodutibildiade e facilidade do código, pensei em fazer um Rmarkdown e um pacote, pois baixar leva tempo e requer mudar o lugar do diretorio para o codigo dar certo…
Imaginei que o Rmarkdown era só para apresentar e que o pacote era necessário para possibilitar a reprodutibilidade completa.
Agora, estudando Rmarkdown, vi que é composto por três fases, o YAML, um lugar onde está os dados; o texto, uma seção usada para escrever o que você quiser; que combina com o código, que você separa com ``` {r} ```.
Nesse sentido minha pergunta é:
- se o que eu quero é passar a base para ser reproduzida sem necessidade de baixar um arquivo e mudar o diretorio para ler,
- se o Rmarkdown tem a seção para colocar os dados YAML, ele é bastante, para evitar o download manual?
- Não há necessidade, portanto, de criar um pacote?
Outra questão, é possível colocar somente dados .R num Rmarkdown ou tem como colocar o PDF raw dentro dele?
Oi Marcello! Tudo bem?
Acredito que criar um pacote ou projeto depende do que você tem como objetivo e as duas formas funcionam. Como é o TCC, me parece que um projeto com um RMarkdown é suficiente para o que você quer fazer.
No YAML, a ideia é colocar informações que funcionam como metadados para os documentos. Também podemos colocar parâmetros a serem usados no relatório.
Para usar os dados do PDF, imagino 2 abordagens:
Abordagem 1
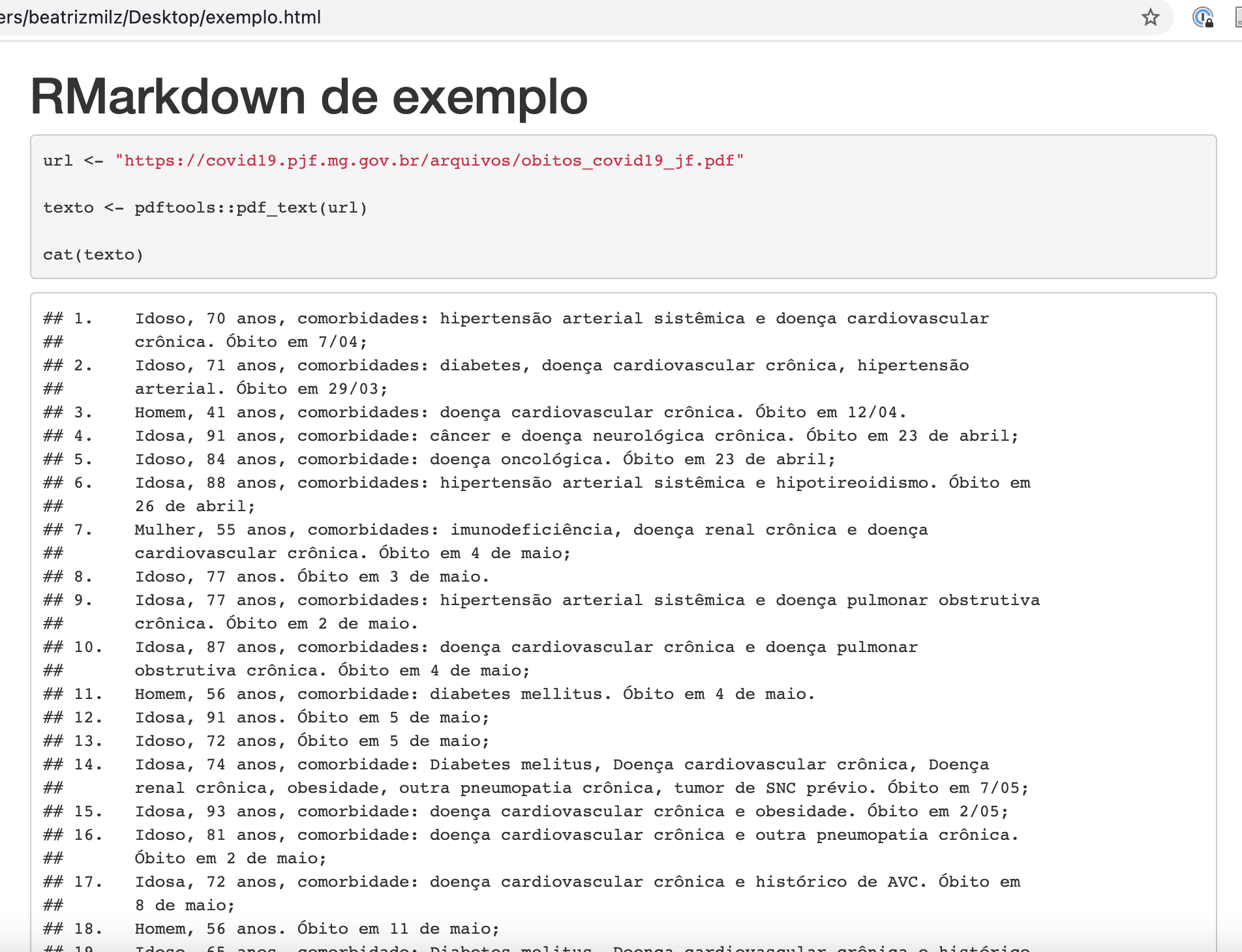
Se a função que você usa aceitar URLs, é possível ler diretamente da URL. Exemplo:
---
title: "RMarkdown de exemplo"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
```{r}
url <- "https://covid19.pjf.mg.gov.br/arquivos/obitos_covid19_jf.pdf"
texto <- pdftools::pdf_text(url)
cat(texto)
```
resultado:
Daí em diante é só seguir limpando os dados…
Abordagem 2
Se você testar a abordagem 1 e não funcionar (então a função que vc usa obriga a baixar os dados), sugiro que coloque no código os passos pra baixar a base localmente e ler ela.
Exemplo
---
title: "RMarkdown de exemplo"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
url <- "https://covid19.pjf.mg.gov.br/arquivos/obitos_covid19_jf.pdf"
fs::dir_create("dados/")
download.file(url, destfile = "dados/obitos_covid19_jf.pdf", method = "curl")
texto <- pdftools::pdf_text("dados/obitos_covid19_jf.pdf")
cat(texto)
Espero ter ajudado! Abraços
Ei @beatrizmilz , não tive tempo de vir te responder, mas só para agradecer que deu muito certo!
Conseguir fazer o Markdown para o TCC do curso. Release Processo de Tidying da Base de óbitos · jfemdados/covid19_pjf · GitHub
muito obrigado!
1 curtida