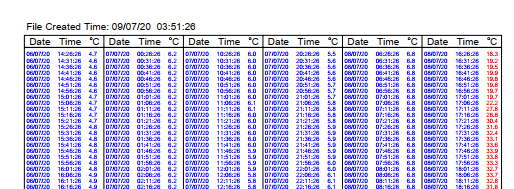
Boa tarde pessoal.
Estou tentando ler várias tabelas (imagem abaixo) de arquivos pdfs com a função extract_tables. Conforme imagem, as variáveis “Date”, “Time” e “ºC” se repetem em outras colunas, então empilhei na sequência cronológica (de “Date”, “Time”). Criei uma estrutura de repetição para extrair dos nomes dos arquivos pdfs (exe.: Jul-2020_AMAZONAS_Volume 12_Inferior) as respectivas informações: Mês, Estado, Volume e Posição e a criar um arquivos .xlsx conforme estrutura a baixo. O código rodou bem até encontra um arquivo pdf com duas páginas, apresentando o seguinte erro:
“Error in (function (…, row.names = NULL, check.rows = FALSE, check.names = TRUE, : **
** arguments imply differing number of rows: 120, 16”
Sei que é um problema simples, mas não estou conseguindo resolvê-lo. Alguém de fórum poderia ajuda neste código :
pdfs<-‘C:/Users/Agosto_2020’
lista<-list.files(pdfs)
temp.lista = list()
for (i in 1:length(lista)) {
nome<-str_split(lista[i], ‘_’,simplify = TRUE)
mes<-nome[1]
estado<-nome[2]
volume<-nome[3]
posicao<-str_sub(nome[4], end=-5)
pdf<-file.path(pdfs,lista[i])
t<-as.data.frame(extract_tables(pdf, output = ‘data.frame’)) %>%
select_if(~ !all(is.na(.))) %>%
data.table() %>%
melt(measure.vars = patterns(‘^Date’,‘^Time’,‘^o’),
value.name = c(‘Data’,‘Hora’,‘Temperatura’)) %>%
select(-variable) %>%
na.exclude() %>%
mutate(Estado = rep(estado, nrow(.)),
Volume = rep(volume, nrow(.)),
Mes = rep(mes,nrow(.)),
Posicao = rep(posicao,nrow(.)),
Tempo = lubridate::as_datetime(paste(Data, Hora),format =“%d/%m/%y %H:%M:%S”)) %>%
select(Mes,Estado,Volume,Posicao,Temperatura,Tempo)
temp.lista[[i]] ← t
}
temp.dados = do.call(bind_rows, temp.lista)
openxlsx::write.xlsx(temp.dados,‘temperatura.xlsx’)
Estrutura do arquivo .xlsx:
| Mes | Estado | Volume | Posicao | Temperatura | Tempo |
|---|---|---|---|---|---|
| Jan-20 | AMAZONAS | Volume 01 | Inferior | 6.5 | 2020/01/20 13:53:18 |
| Jan-20 | AMAZONAS | Volume 01 | Inferior | 5.9 | 2020/01/20 13:58:18 |
| Jan-20 | AMAZONAS | Volume 01 | Meio | 5.7 | 2020/01/20 14:03:18 |
| Jan-20 | AMAZONAS | Volume 01 | Meio | 5.6 | 2020/01/20 14:08:18 |
| Jan-20 | AMAZONAS | Volume 01 | Superior | 5.7 | 2020/01/20 14:13:18 |
| Jan-20 | AMAZONAS | Volume 01 | Superior | 5.7 | 2020/01/20 14:18:18 |
| Jan-20 | ACRE | Volume 01 | Inferior | 5.7 | 2020/01/20 14:23:18 |
| Jan-20 | ACRE | Volume 01 | Inferior | 5.8 | 2020/01/20 14:28:18 |
| Jan-20 | ACRE | Volume 01 | Meio | 5.8 | 2020/01/20 14:33:18 |
| Jan-20 | ACRE | Volume 01 | Meio | 5.9 | 2020/01/20 14:38:18 |
| Jan-20 | ACRE | Volume 01 | Superior | 5.9 | 2020/01/20 14:43:18 |
| Jan-20 | ACRE | Volume 01 | Superior | 6 | 2020/01/20 14:48:18 |