Oi Pessoal,
Estou trabalhando com um arquivo (disponível aqui) que contém blocos anuais de informações diárias de chuva, como mostrado (parcialmente) na imagem abaixo.
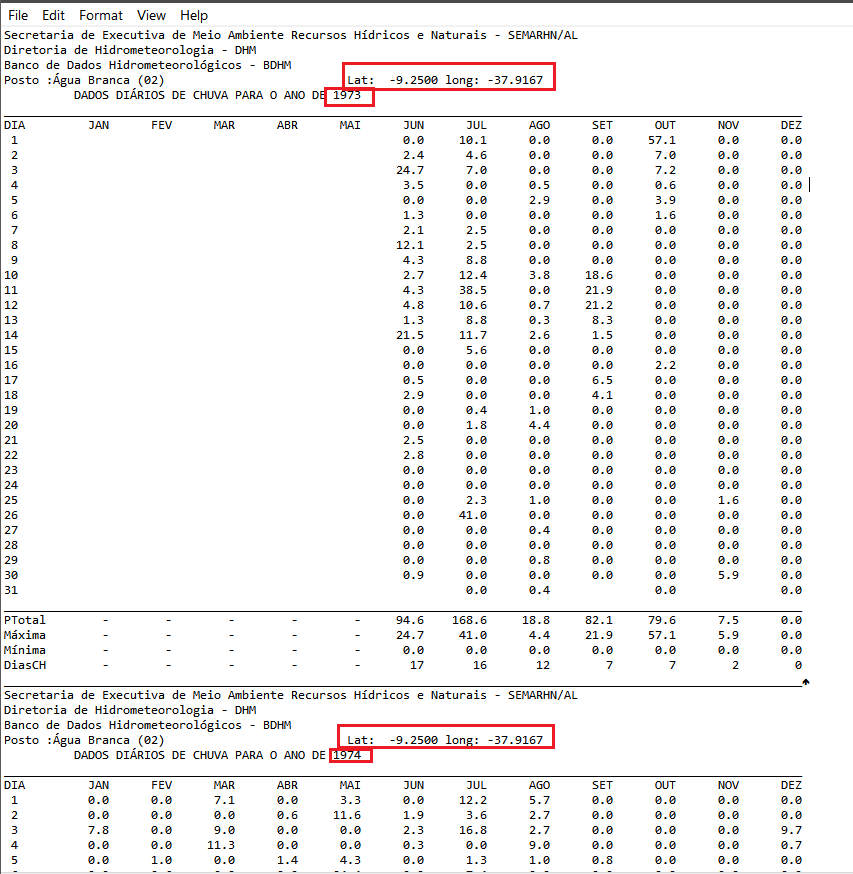
Venho tentando fazer a leitura e organização deste arquivo de modo que eu possa ter ao final um data.frame ou tibble com colunas: “name_file”, “lon”, “lat”, “data” e “prec”. Talvez não seja a melhor forma mas pensei em fazer a leitura de cada bloco separadamente uilizando uma estrutura de repetição. Abaixo tem o uso da função read.table() para leitura do primeiro bloco de informação:
read.table("DiarioÁgua Branca (02).wri", header = T, skip = 6,
fill = T, nrows = 31)
#> DIA JAN FEV MAR ABR MAI JUN JUL AGO SET OUT NOV DEZ
#> 1 1 0.0 10.1 0.0 0.0 57.1 0.0 0 NA NA NA NA NA
#> 2 2 2.4 4.6 0.0 0.0 7.0 0.0 0 NA NA NA NA NA
#> 3 3 24.7 7.0 0.0 0.0 7.2 0.0 0 NA NA NA NA NA
#> 4 4 3.5 0.0 0.5 0.0 0.6 0.0 0 NA NA NA NA NA
#> 5 5 0.0 0.0 2.9 0.0 3.9 0.0 0 NA NA NA NA NA
#> 6 6 1.3 0.0 0.0 0.0 1.6 0.0 0 NA NA NA NA NA
#> 7 7 2.1 2.5 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 8 8 12.1 2.5 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 9 9 4.3 8.8 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 10 10 2.7 12.4 3.8 18.6 0.0 0.0 0 NA NA NA NA NA
#> 11 11 4.3 38.5 0.0 21.9 0.0 0.0 0 NA NA NA NA NA
#> 12 12 4.8 10.6 0.7 21.2 0.0 0.0 0 NA NA NA NA NA
#> 13 13 1.3 8.8 0.3 8.3 0.0 0.0 0 NA NA NA NA NA
#> 14 14 21.5 11.7 2.6 1.5 0.0 0.0 0 NA NA NA NA NA
#> 15 15 0.0 5.6 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 16 16 0.0 0.0 0.0 0.0 2.2 0.0 0 NA NA NA NA NA
#> 17 17 0.5 0.0 0.0 6.5 0.0 0.0 0 NA NA NA NA NA
#> 18 18 2.9 0.0 0.0 4.1 0.0 0.0 0 NA NA NA NA NA
#> 19 19 0.0 0.4 1.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 20 20 0.0 1.8 4.4 0.0 0.0 0.0 0 NA NA NA NA NA
#> 21 21 2.5 0.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 22 22 2.8 0.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 23 23 0.0 0.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 24 24 0.0 0.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 25 25 0.0 2.3 1.0 0.0 0.0 1.6 0 NA NA NA NA NA
#> 26 26 0.0 41.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 27 27 0.0 0.0 0.4 0.0 0.0 0.0 0 NA NA NA NA NA
#> 28 28 0.0 0.0 0.0 0.0 0.0 0.0 0 NA NA NA NA NA
#> 29 29 0.0 0.0 0.8 0.0 0.0 0.0 0 NA NA NA NA NA
#> 30 30 0.9 0.0 0.0 0.0 0.0 5.9 0 NA NA NA NA NA
#> 31 31 0.0 0.4 0.0 0.0 NA NA NA NA NA NA NA NA
Created on 2022-03-21 by the reprex package (v2.0.1)
Sobre esta abordagem, observe que encontro o primeiro problema: os meses de agosto (AGO) a dezembro (DEZ) recebem NA, porém, são os meses de janeiro (JAN) a maio (MAI) que devem receber NA, como visto na imagem acima. Tentei fazer a leitura também com readLines() mas não obtive grande avanço. Qualquer ajuda na leitura e organização desses dados é bem-vinda. Muito obrigado!

 fico feliz!
fico feliz!