Prezadxs, olá!
Estou realizando um trabalho com extrações de tabelas de pdfs e cheguei em arquivos onde preciso usar OCR (com o pdftools + tesseract) pra conseguir capturar algo. O problema é que o resultado obtido é totalmente um texto e eu não sei exatamente como extrair a tabela , tenho uma vaga noção que é usando Regex, porém não encontrei nenhum exemplo bom pra estudar.
Dúvida: alguém poderia dar um help na extração dessa? Ou compartilhar algum exemplo semelhante de extração de tabela diretamente de um texto?
Como tenho várias tabelas diferentes onde devo realizar o procedimento, aprendendo como se faz para uma tabela, eu consigo adaptar e aplicar o conhecimento em outras.
Segue código de exemplo:
# Carregar e instalar pacotes ---------------------------------------------
# if(!require("pacman")) install.packages("pacman")
# pacman::p_load(tidyverse, pdftools, tesseract, janitor)
# Carregar pipe
'%>%' <- magrittr::`%>%`
# Importar pdfs -----------------------------------------------------------
# AGEFLOR - A Indústria de Base Florestal no RS - 2017
# Nesse relatório as tabelas estão como imagens
url_ageflor_2017 <- "https://github.com/maykongpedro/2021-07-04-extracao-mapeamentos-plantios-florestais/raw/master/data-raw/pdf/04-RS/ageflor_setor_florestal_2017.pdf"
# Extraindo infos
ageflor_2017 <- pdftools::pdf_ocr_text(url_ageflor_2017)
#> Converting page 1 to ageflor_setor_florestal_2017_1.png... done!
#> Converting page 2 to ageflor_setor_florestal_2017_2.png... done!
#> Converting page 3 to ageflor_setor_florestal_2017_3.png... done!
#> Converting page 4 to ageflor_setor_florestal_2017_4.png... done!
#> Converting page 5 to ageflor_setor_florestal_2017_5.png... done!
#> Converting page 6 to ageflor_setor_florestal_2017_6.png... done!
# 0lhando apenas a página 1
ageflor_2017 %>%
purrr::pluck(1) %>%
cat()
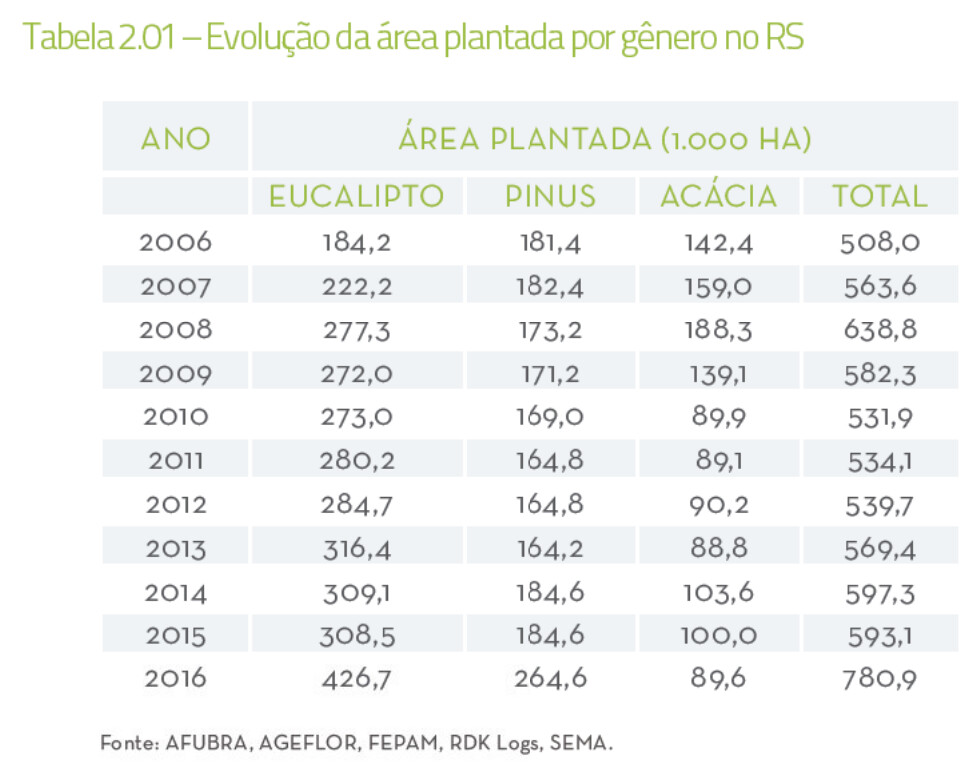
#> O histérico da area plantada no Rio Grande do Sul é apresentada na Tabela
#> 2.01 e Figura 2.04. Ressalte-se que a diferenca significativa da area plantada
#> do ano de 2015 para 2016 nao reflete aumento da area plantada, mas sim uma
#> maior disponibilidade de dados e mudanga na metodologia de levantamento
#> das informacées.
#> Tabela 2.01 —Evolucao da area plantada por genero no RS
#> ANO AREA PLANTADA (1.000 HA)
#> EUCALIPTO PINUS ACACIA TOTAL
#> 2006 184,2 181,4 142,4 508,0
#> 2007 222,2 182,4 159,0 563,6
#> 2008 277,53 173,2 188,3 638,8
#> 2009 272,0 171,2 139,1 582,3
#> 2010 273,0 169,0 89,9 531,9
#> 2011 280,2 164,8 89,1 5341
#> 2012 284,7 164,8 90,2 539.7
#> 2013 316,4 164,2 88,8 569,4
#> 2014 309,] 184,6 103,6 597,35
#> 2015 308,5 184,6 100,0 593,1
#> 2016 426,7 264,6 89,6 780,9
#> Fonte: AFUBRA, AGEFLOR, FEPAM, RDK Logs, SEMA.
#> Figura 2.04 — Evolucao da area plantada por género no RS
#> D 2 © 90
#> 7H
#> :
#> Es
#> &
#> =
#> S
#> <
#> 2006 2007 - 2008 2009 ~ 2010 - 2011 2012 2013 2014 2015 2016
#> MeEucalipto gPinus Acacia
#> Nota: Os dados referentes aos plantios de acacia em 2009 foram estimados pela Consufor (2016).
#> Fonte: AGEFLOR / Adaptagcao: RDK Logs.
#> 15
# Como eu capturo apenas a tabela?
A tabela da página 1 é a imagem a seguir:
Created on 2021-07-15 by the reprex package (v2.0.0)
Agradeço qualquer ajuda!
Abraços.