Julio, olá! estou tentando fazer a raspagem dos dados do endereço:
https://www3.bcb.gov.br/ifdata/index.html#
para 2000/03, Conglomerados e RESUMO, por exemplo. O problema é que o resultado que me interessa, aparece em formato CSV que precisa ser clicado quando a pesquisa é montada, pior, preciso ir salvando esses arquivos CSV. Tentei raspar diretamente do que aparece na pesquisa, contudo o resultado monta errado o resultado no R. Agradeço a ajuda! Grande abraço!
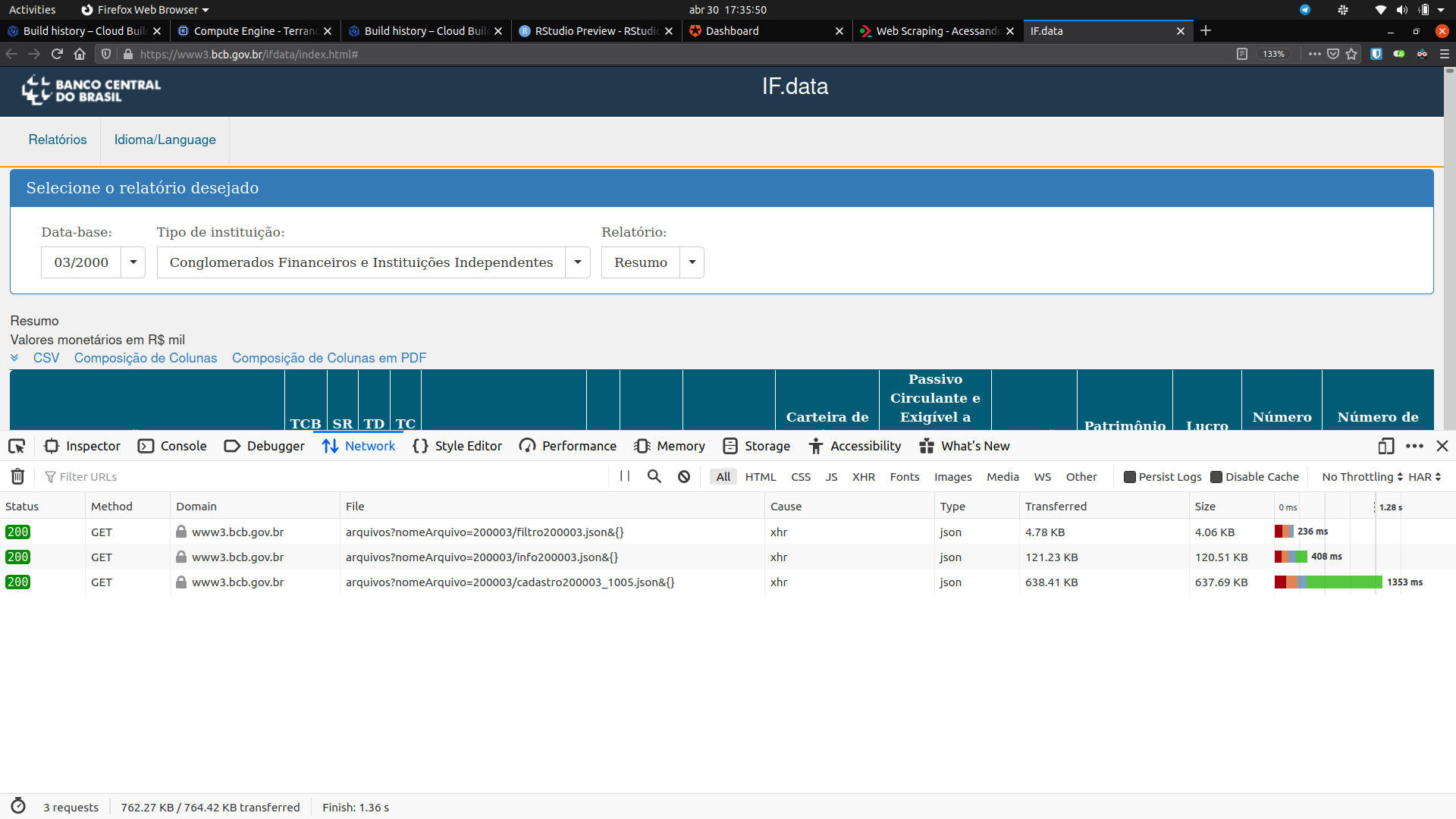
André, me parece que você encontrou um feliz caso de API escondida por trás do site \o/
Veja o print screen:
Os três arquivos JSON que ele busca são justamente os dados que alimentam o a tabela que você quer acessar. Por exemplo, para acessar o primeiro, eu faria
library(magrittr)
u <- "https://www3.bcb.gov.br/ifdata/rest/arquivos?nomeArquivo=200003/filtro200003.json&{}"
r <- httr::GET(u)
da <- httr::content(r, simplifyDataFrame = TRUE) %>%
tibble::tibble()
da
#> # A tibble: 5 x 6
#> id n ni fi ii d
#> <int> <chr> <chr> <int> <int> <list>
#> 1 1 TCB - Tipo de Consoli… TCB - Business Model Cat… 1 79671 <df[,4] [7…
#> 2 2 TC - Tipo de Controle TC - Control 1 79676 <df[,4] [3…
#> 3 3 TD - Tipo de Consolid… TD - Aggregation type 1 79675 <df[,4] [2…
#> 4 4 TI - Tipo de Institui… TI - Types 1 79680 <df[,4] [2…
#> 5 5 SR - Segmento Resoluç… SR - Resolution nº 4.553… 1 79679 <df[,4] [5…
# para "explodir" os conteúdos da coluna "d"
da %>%
tidyr::unnest(d, names_sep = "_")
#> # A tibble: 39 x 9
#> id n ni fi ii d_id d_v d_n d_ni
#> <int> <chr> <chr> <int> <int> <int> <chr> <chr> <chr>
#> 1 1 TCB - Ti… TCB - B… 1 79671 1 b1 b1 - Banco Co… b1 - Commerc…
#> 2 1 TCB - Ti… TCB - B… 1 79671 2 b2 b2 - Banco Mú… b2 - Univers…
#> 3 1 TCB - Ti… TCB - B… 1 79671 3 b3S b3S - Coopera… b3S - Credit…
#> 4 1 TCB - Ti… TCB - B… 1 79671 4 b3C b3C - Central… b3C - Centra…
#> 5 1 TCB - Ti… TCB - B… 1 79671 5 b4 b4 - Banco de… b4 - Develop…
#> 6 1 TCB - Ti… TCB - B… 1 79671 6 n1 n1 - Não Banc… n1 - Non Ban…
#> 7 1 TCB - Ti… TCB - B… 1 79671 7 n2 n2 - Não Banc… n2 - Non Ban…
#> 8 2 TC - Tip… TC - Co… 1 79676 1 1 1 - Público 1 - Governme…
#> 9 2 TC - Tip… TC - Co… 1 79676 2 2 2 - Privado N… 2 - Domestic…
#> 10 2 TC - Tip… TC - Co… 1 79676 3 3 3 - Privado c… 3 - Foreign …
#> # … with 29 more rows
Created on 2020-04-30 by the reprex package (v0.3.0)
Para pegar todos os dados, basta substituir os endpoints (parece que são “filtro”, “info” e “cadastro”), bem como as datas correspondentes.
Boa sorte 
4 curtidas