Eu queria scrappar a página que vem com “Ementas e Documentos do Processo” que alguns têm a ementa da decisão e até o inteiro teor, além links para outros documentos em pdfs.
No site da Epagri tem os preços diários praticados pelo mercado agrícola no estado de Santa Catarina. Preciso baixar os arquivos e fazer análises semanais.
Cada dia é um link para uma base de dados, gostaria de poder baixar automaticamente todas essas bases, e não uma a uma haha (manual). A faxina e organização das mesmas é algo que com um pouco de prática consigo resolver, o problema é o download automático mesmo.
Se der boa, show. Não tenho certeza se entra dentro dos requisitos da live.
Um site que já foi pedido aqui e aparece em todos os fóruns sobre web scraping é o Whoscored. Eu já até consegui capturar algumas coisas usando Selenium, com Python, mas foi muito na tentativa e erro, a real é que eu não consigo entender qual técnica devo aplicar para esse tipo de site.
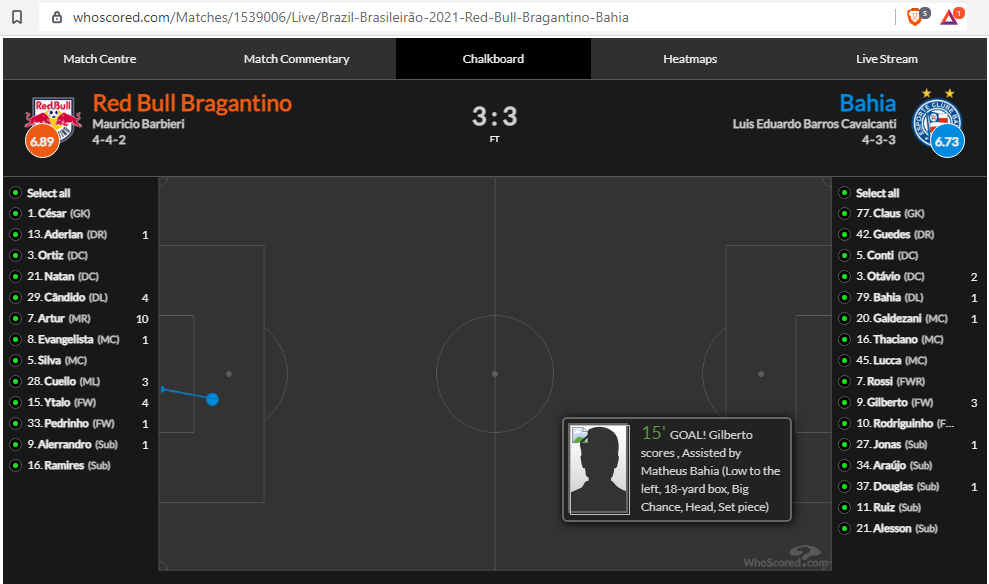
Nessa página o que eu queria era, lá embaixo onde tem o campinho, clicando em ‘Chalkboard’ se vê vários pontinhos. Se eu clico em um deles, me traz a descrição completa da ação (ver imagem abaixo). Meu sonho é baixar os atributos de cada ponto aí (a localização + a descrição).
Tudo que é texto e número na página eu até consegui, simulando uma navegação com Selenium, mas simular esse clique no ponto não rolou. O problema desse meu “método”, é que não é escalável.
Tentei raspar os dados do Eschmeyer’s Catalog of Fishes recentemente e falhei miseravelmente kkkk Esse é o site referência mundialmente para taxonomia de peixes.
Eu consegui puxar a tabela do Genera/Species by Family/Subfamily pelo Google Planilhas mesmo kkkk e posso arrumar os nomes por Ordem, Família e Subfamília já que todos usam o mesmo sufixo por grupo. Planilha
O que seria interessante que não sei fazer, seria fazer a busca no site principal e retornar o texto como resultado.
Ex buscando “cichla kelberi”:
Estou tentando fazer uma função para puxar os dados históricos dos reservatórios da SABESP para implementar no pacote reservatoriosBR, que já divulguei aqui.
Por esse link é possível selecionar as variáveis a serem buscadas (datas e sistema ali que nesse caso é 0).
No entanto tenho muita dificuldade na transformação desses dados (em JSON) em um dataframe no R. São várias listas dentro de listas dentro de listas kkkkk
Alguém poderia ajudar?
Com a crise hídrica, seria bem importante utilizar esses dados em análises.
Caso alguém queira contribuir com o pacote, ajudando no desenvolvimento de funções etc, é só entrar em contato!
Perdoe-me o engano, caso não seja o que estou entendendo, mas isso que você está tentando fazer não é algo semelhante ao pacote implementado pela @beatrizmilz?
Nossa, você tem razão! Não sabia da existência desse pacote. E hoje esbarrei nos dados da SABESP e pensei em implementar no reservatoriosBR. Mas esse pacote da Beatriz é perfeito! Vou inclusive citar na descrição do meu! Parabéns @beatrizmilz pelo trabalho!!!
Caaaara, não acredito que perdi bem essa live! Infelizmente não consegui assistir
Acabei de assistir agora, e vocês mandaram bem demais!!! (Menos na parte relativa à biologia, mas estão perdoados kkkkk)
Vou tentar adaptar esse código com o que utilizamos e dou um retorno aqui também!
Mas a tibble ficou incrível!
E parabéns pela live, foi muito boa, aprendi muito!
Um site do governo importante é a seção de Consultas Públicas, que muitas vezes são abertas e passam despercebidas pela população.
Como visto na reportagem da Agência Pública, o governo fez uma consulta pública de 30 de março a 29 de abril deste ano sobre um programa de fracking, extração de gás e óleo atualmente proibida no Brasil, (a ser lançado nesse mês de junho), e tivemos só 5 (??) contribuições.
O site de Consulta Pública em questão é o do Ministério de Minas e Energias, mas talvez se os outros seguirem o mesmo padrão, poderíamos só exportar.
Uma base de dados com título, subtitulo, prazo inicial e final, status e link já seria bem legal!