Total de comentários de users no TripAdvisor num restaurante/hotel.
Em cada review devemos retirar:
Comentários do user:
- Título do post
- Comentário
- Data do post
- Nr de votos úteis
Resposta do hotel/restaurante:
- Nome do “gestor”
- Data
- Resposta
Dados do user que publicou o comentário:
-
Nome
-
Nr de contributos
-
Nr total votos úteis
-
País
-
Cidade
Sugestão: Dados de Microempreendedores individuais (MEI ) no Brasil, onde na pandemia tem se observado que a quantidade de MEIs tem aumentado consideravelmente.
O site oferece uma gama de informações, como quantidade de MEI por mês e município, segregações por atividade econômica, sexo, dentre outras.
Preciso baixar diariamente e excel no fim da página. Não sei a dificuldade, só sei que o link de download não é estático. Ele é gerado com algum tipo de hash.
https://data.humdata.org/dataset/e1a91ae0-292d-4434-bc75-bf863d4608ba
Sorry, tripadvisor não rola por conta das (potenciais) políticas de dados deles 
Sorry, webmotors não rola por conta das (potenciais) políticas de dados deles
A API do openDataSUS com os registros de casos de COVID-19 https://opendatasus.saude.gov.br/dataset/casos-nacionais/resource/30c7902e-fe02-4986-b69d-906ca4c2ec36
Tive um pouco de dificuldade ao explorar por conta própria
Galera, boa tarde!
Sou aluno do curso de Web Scraping em andamento. Estou com bastante dificuldade para explorar a página de pesquisa de jurisprudencia do STF. Os comandos GET e read_html retornam objetos bem pequenos e eu não consegui explorá-los… Peço ajuda de todos, em especial do Julio e do Caio rs.
Trata-se de uma demanda do trabalho mesmo, adoraria conseguir explorar esta página com R.
Obs: este é um exemplo de pesquisa, com o termo “covid”
Atualização 1: usei html_structure( ) para achar os nós. O que retorna do R é bem menor do que aparece ao inspecionar a página. Tentei abrir no navegador uns ponteiros de páginas em .js, porém nada se parece com a página real. Acho que a requisição está errada mesmo rs.
Atualização 2: Nem com RSelenium eu consegui. Aparece um erro “Compound class names not permitted”. A requisição retorna um objeto que contém apenas o esqueleto do HTML. Não consigo acessar nós filhos…
Sugestão:
Pegar os dados das escolas Estaduais do Estado da Bahia.
Aparentemente, é um scraping “Muitas buscas e muitas paginações por busca”.
No caso, a página principal tem o nome da escola e um link para acessar mais informações.
A página principal é essa: http://escolas.educacao.ba.gov.br/escolas
Um exemplo de página com os detalhes do colégio: http://escolas.educacao.ba.gov.br/node/11983
O desafio seria pegar as demais informações sobre a escola. Ex: dados cadastrais; georreferenciamento do Google Maps (talvez seja um javascript, não sei ao certo).
Uma dúvida que sempre tive é se há, no padrão HTML, uma forma de navegar entre as subpáginas.
Lá no instagram deram as seguintes sugestões:
http://educacaoconectada.mec.gov.br/consulta-pdde
https://www.flamengo.com.br/titulosdoflamengo (esse aqui tem bastante faxina)
currículo lattes
olx
Olha, vamos aqui com um pouco de jurimetrics.
Eu to pesquisando autorregulação da B3, feita pela BSM, e até comecei a fazer um scrapper dos processos administrativos da BSM.
A listagem com todos os processos está aqui: https://www.bsmsupervisao.com.br/atividades-disciplinares-e-processos/acompanhe-os-processos
Dos dados de cada processo, esse link “exportar para o excel” gera todas as informações que estão presentes no link acima e no https://www.bsmsupervisao.com.br/atividades-disciplinares-e-processos/acompanhe-os-processos/detalhes/PAD-001/2008 , que são detalhes/PAD-001/2008. Até aqui não há necessidade de web scrapping.
Eu queria scrappar a página que vem com “Ementas e Documentos do Processo” que alguns têm a ementa da decisão e até o inteiro teor, além links para outros documentos em pdfs.
Parsear, de modo uniforme algumas páginas que as vezes tem ementas, as vezes não tem, as vezes só links, tem sido uma certa dificuldade pra mim. Eu tentei usando aquele método que vcs usaram na outra live, olhando o padrão do site e dando paste(“https://www.bsmsupervisao.com.br/atividades-disciplinares-e-processos/acompanhe-os-processos/parecer/”, str_extract("\d*\-\d*),"-pad") .
o httr rolou, mas o parse parou aí! kk
Os dados são públicos e não tem captcha!
Dados de vacinação do governo federal
https://qsprod.saude.gov.br/extensions/DEMAS_C19Vacina/DEMAS_C19Vacina.html
Opa, aproveitar a deixa!
No site da Epagri tem os preços diários praticados pelo mercado agrícola no estado de Santa Catarina. Preciso baixar os arquivos e fazer análises semanais.
No seguinte site eu entro escolho o mês:
https://cepa.epagri.sc.gov.br/index.php/produtos/mercado-agricola/precos-agricolas-diario-indice/
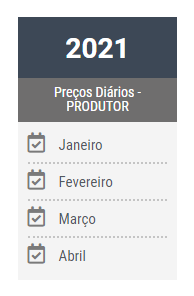
Depois disso abre a seguinte página (mês de março):
https://cepa.epagri.sc.gov.br/index.php/produtos/mercado-agricola/Precos-agricolas-diario-Mar-2021/
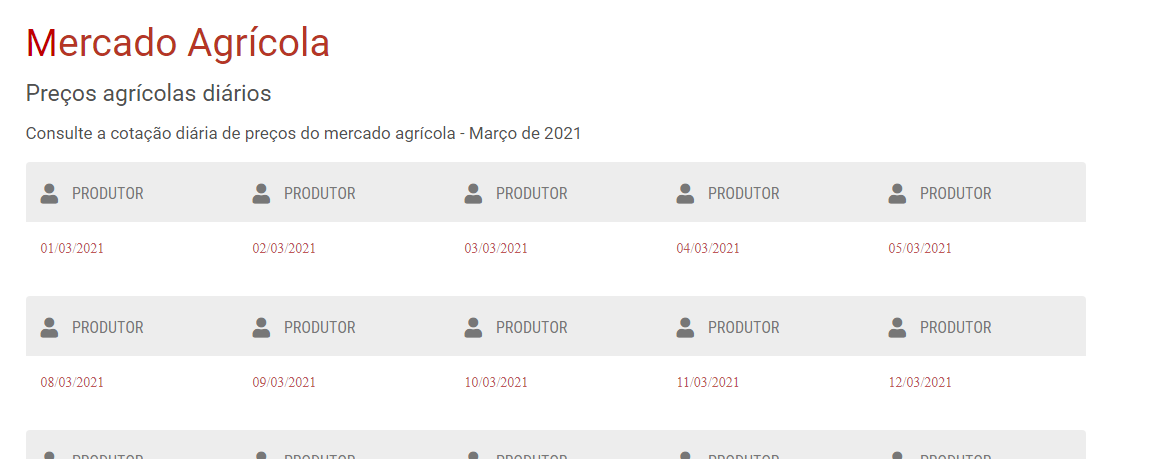
Cada dia é um link para uma base de dados, gostaria de poder baixar automaticamente todas essas bases, e não uma a uma haha (manual). A faxina e organização das mesmas é algo que com um pouco de prática consigo resolver, o problema é o download automático mesmo.
Se der boa, show. Não tenho certeza se entra dentro dos requisitos da live.
Muito obrigado!
Abraços.
Um site que já foi pedido aqui e aparece em todos os fóruns sobre web scraping é o Whoscored. Eu já até consegui capturar algumas coisas usando Selenium, com Python, mas foi muito na tentativa e erro, a real é que eu não consigo entender qual técnica devo aplicar para esse tipo de site.
Aqui vai o link:
https://www.whoscored.com/Matches/1539006/Live/Brazil-Brasileirão-2021-Red-Bull-Bragantino-Bahia
Nessa página o que eu queria era, lá embaixo onde tem o campinho, clicando em ‘Chalkboard’ se vê vários pontinhos. Se eu clico em um deles, me traz a descrição completa da ação (ver imagem abaixo). Meu sonho é baixar os atributos de cada ponto aí (a localização + a descrição).
Tudo que é texto e número na página eu até consegui, simulando uma navegação com Selenium, mas simular esse clique no ponto não rolou. O problema desse meu “método”, é que não é escalável.
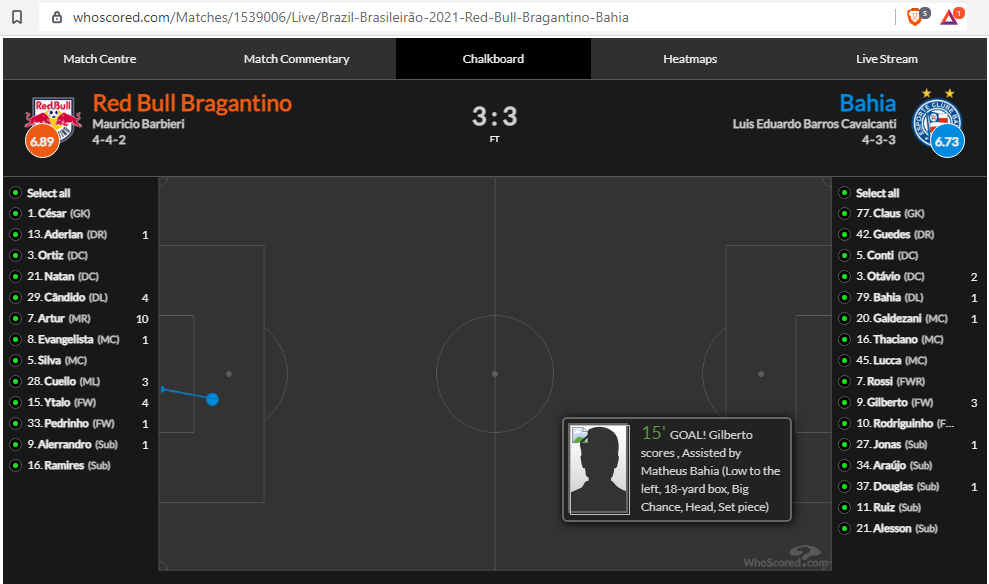
Tentei mexer nesse site e bloquearam meu ip =( kkk. Acho que eles não querem ser scrapeados!
Tentei raspar os dados do Eschmeyer’s Catalog of Fishes recentemente e falhei miseravelmente kkkk Esse é o site referência mundialmente para taxonomia de peixes.
O link do site é CAS - Eschmeyer's Catalog of Fishes:
Se desse pra raspar a tabela do CAS - Eschmeyer's Catalog of Fishes - Genera/Species by Family/Subfamily já seria uma mão na roda
Eu consegui puxar a tabela do Genera/Species by Family/Subfamily pelo Google Planilhas mesmo kkkk e posso arrumar os nomes por Ordem, Família e Subfamília já que todos usam o mesmo sufixo por grupo.
Planilha
O que seria interessante que não sei fazer, seria fazer a busca no site principal e retornar o texto como resultado.
Ex buscando “cichla kelberi”:

O OpenDataSUS é um repositório do CKAN. Tem uma API por trás que dá para usar alguns atalhos.
Estou tentando fazer uma função para puxar os dados históricos dos reservatórios da SABESP para implementar no pacote reservatoriosBR, que já divulguei aqui.
Por esse link é possível selecionar as variáveis a serem buscadas (datas e sistema ali que nesse caso é 0).
No entanto tenho muita dificuldade na transformação desses dados (em JSON) em um dataframe no R. São várias listas dentro de listas dentro de listas kkkkk
Alguém poderia ajudar?
Com a crise hídrica, seria bem importante utilizar esses dados em análises.
Caso alguém queira contribuir com o pacote, ajudando no desenvolvimento de funções etc, é só entrar em contato!

Bruno, olá!
Perdoe-me o engano, caso não seja o que estou entendendo, mas isso que você está tentando fazer não é algo semelhante ao pacote implementado pela @beatrizmilz?
Veja se encontra alguma dica nos códigos do pacote.
Abraços.