Muito agradecido, deu certo aqui, aproveitei para fazer uns filtros e dar uma alinhada no código para deixar pronto para fazer análises, vou postar abaixo.
Só uma observação, quando você fez a importação e deu o comando tibble::as_tibble(), ele comeu as casas decimais do valor unitário do título, troquei este comando por data.table::data.table()
library(tidyverse)
u <- “https://www.tesourodireto.com.br/json/br/com/b3/tesourodireto/service/api/treasurybondsinfo.json”
r <- httr::GET(u, httr::config(ssl_verifypeer = FALSE))
da_tesouro <- httr::content(r, simplifyDataFrame = TRUE) %>%
purrr::pluck(“response”, 3, 1) %>%
data.table::data.table() %>%
janitor::clean_names()
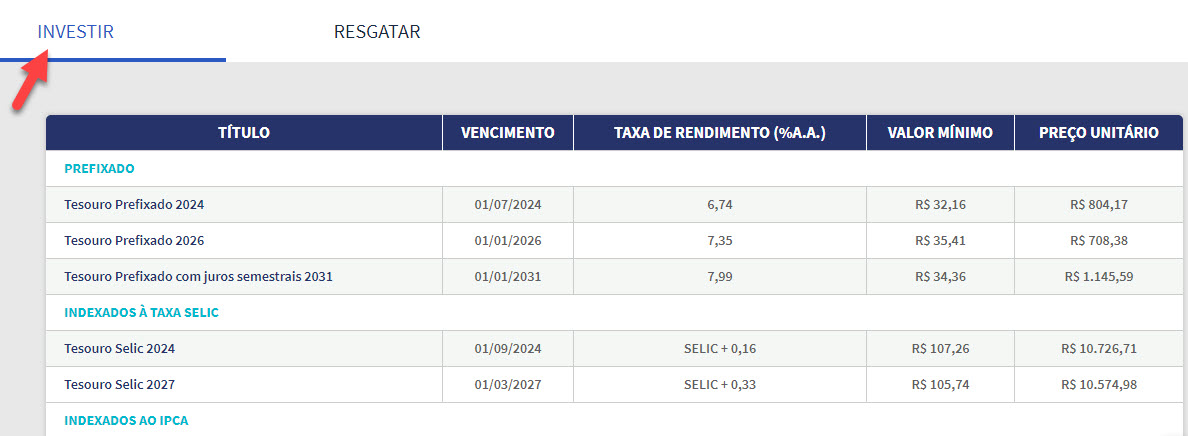
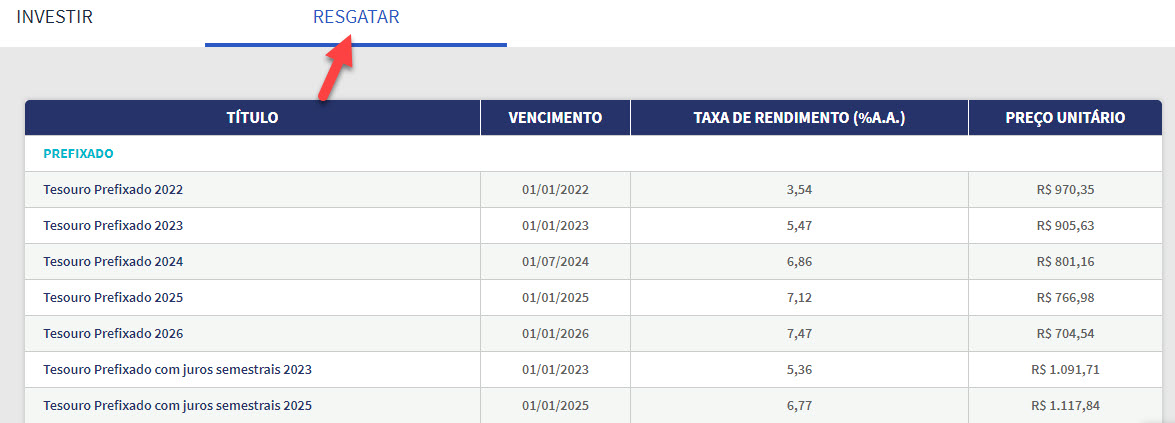
x2 <- da_tesouro %>% select(fin_indxs_nm, mtrty_dt, min_invstmt_amt, untr_invstmt_val, untr_red_val, semi_anul_intrst_ind, anul_invstmt_rate, anul_red_rate, wdwl_dt)
x2$mtrty_dt <- substr(x2$mtrty_dt, start=1, stop=10) %>% as.Date()
x2$wdwl_dt <- substr(x2$wdwl_dt, start=1, stop=10) %>% as.Date()
x2 <- x2 %>% rename(“indice” = “fin_indxs_nm”,
“vcto” = “mtrty_dt”,
“inv_min” = “min_invstmt_amt”,
“vlr_un_comp” = “untr_invstmt_val”,
“vlr_un_venda” = “untr_red_val” ,
“cupom” = “semi_anul_intrst_ind”,
“ret_inv” = “anul_invstmt_rate”,
“ret_resgate” = “anul_red_rate”,
“data_emissao” = “wdwl_dt” ) %>%
select(“indice”, “vcto”, “cupom”, “inv_min”, “vlr_un_comp”, “vlr_un_venda”, “ret_inv”, “ret_resgate”, “data_emissao”)
x2
x2_compra <- x2 %>% filter(inv_min>0) %>% select(-c(data_emissao, ret_resgate, vlr_un_venda))
x2_venda <- x2 %>% select(-c(inv_min,data_emissao, vlr_un_comp, ret_inv))