Fala Victor, tudo bem?
Analisei aqui a API do site da Trígono e percebi o seguinte. O caminho da API que acessa os Conteúdos da Trígono que envolve resenhas mensais e outros, é https://api.trigonocapital.com/contents?page=X&locale_id=1&category_id=5.
Se você fuçar, verá que os category_id se referem a aba de Conteúdos, sendo a distribuição assim:
{
{"id": 1, "name": "biblioteca"},
{"id": 2, "name": "na-midia"},
{"id": 5, "name": "conteudo-trigono"},
{"id": 6, "name": "lives-trigono"}
}
Ou seja, você pode utilizar a API sabendo do que se trata. Vi que o parâmetro locale_id=1 não tem variação importante, e no seu caso não impacta em nada. Vamos consultar a API então:
# Requisição GET
httr::GET("https://api.trigonocapital.com/contents?page=1&locale_id=1&category_id=5") |>
httr::content() |> # Leitura do Conteúdo
purrr::pluck("data") |> # Pegando apenas a parte dos dados
purrr::map(
~ purrr::pluck(.x, "pdf_url") # Indo em cada elemento, e puxando o conteúdo de "pdf_url"
) |>
unlist()
#> [1] "https://api.trigonocapital.com/files/contents/ab73afa3-f346-4195-9fb2-02e66def6e84.pdf"
#> [2] "https://api.trigonocapital.com/files/contents/e2539d8e-a0c2-47a6-b09b-f5ae5ee74673.pdf"
#> [3] "https://api.trigonocapital.com/files/contents/e9d87d0e-246e-47e1-a270-b1ec21ada669.pdf"
#> [4] "https://api.trigonocapital.com/files/contents/b29ff8e2-019b-49cb-96e0-2d088a04ffe8.pdf"
#> [5] "https://api.trigonocapital.com/files/contents/d08d5b6d-5d61-4f96-8f9d-4bc1b2ec9db8.pdf"
Perceba, aqui eu fiz apenas para page=1. Se eu quisesse pegar de todas as páginas disponíveis, bastava iterar sobre a URL. Para facilitar ainda mais, a resposta da requisição nos traz a informação de quantas páginas existem:
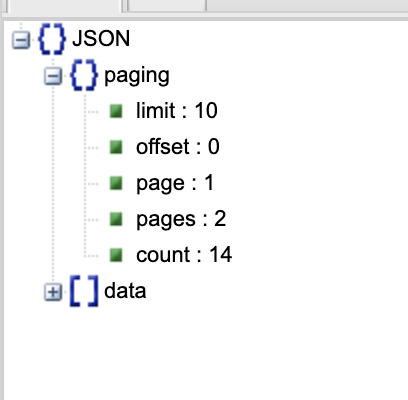
(Obs: para você conseguir ver a estrutura do JSON de forma bonitinha, use o Online JSON Viewer. Coloque em “Text” o JSON encontrado na URL da API, e clique em Viewer para ter acesso a essa visualização).
Voltando a paginação.
# Acessa o conteúdo
httr::GET("https://api.trigonocapital.com/contents?page=1&locale_id=1&category_id=5") |>
httr::content() -> conteudo
# Acesso a quantidade de páginas
pages <- conteudo |>
purrr::pluck("paging", "pages")
# Funcão para podermos iterar sobre ela
trigono_api <- function(page){
glue::glue("https://api.trigonocapital.com/contents?page={page}&locale_id=1&category_id=5") |>
httr::GET() |>
httr::content() |>
purrr::pluck("data") |>
purrr::map(
~ purrr::pluck(.x, "pdf_url")
) |>
unlist()
}
purrr::map(
.x = seq(1, pages), # seq(1, 6)
.f = ~ trigono_api(.x)) |>
purrr::flatten_chr() # listas --> único vetor
#> [1] "https://api.trigonocapital.com/files/contents/ab73afa3-f346-4195-9fb2-02e66def6e84.pdf"
#> [2] "https://api.trigonocapital.com/files/contents/e2539d8e-a0c2-47a6-b09b-f5ae5ee74673.pdf"
#> [3] "https://api.trigonocapital.com/files/contents/e9d87d0e-246e-47e1-a270-b1ec21ada669.pdf"
#> [4] "https://api.trigonocapital.com/files/contents/b29ff8e2-019b-49cb-96e0-2d088a04ffe8.pdf"
#> [5] "https://api.trigonocapital.com/files/contents/d08d5b6d-5d61-4f96-8f9d-4bc1b2ec9db8.pdf"
#> [6] "https://api.trigonocapital.com/files/contents/d9305426-6cbd-481b-899c-00686a2eccf2.pdf"
#> [7] "https://api.trigonocapital.com/files/contents/0619b050-9f29-469c-a2ac-bbe441c32f64.pdf"
#> [8] "https://api.trigonocapital.com/files/contents/f4543d37-adfd-4ba1-b24c-b178c06df8ac.pdf"
#> [9] "https://api.trigonocapital.com/files/contents/9d4a7ccc-465e-4c3f-b55f-671ebe8e5cf6.pdf"
#> [10] "https://api.trigonocapital.com/files/contents/820587eb-e915-48d9-b952-687c4b6f8206.pdf"
#> [11] "https://api.trigonocapital.com/files/contents/a7b65a37-906f-40f2-abfa-efef63eddfe8.pdf"
#> [12] "https://api.trigonocapital.com/files/contents/27d608c3-3423-43a5-bc0d-f7e9520200d6.pdf"
#> [13] "https://api.trigonocapital.com/files/contents/461f2b28-b9b6-48cc-88c6-9a56af7e6806.pdf"
#> [14] "https://api.trigonocapital.com/files/contents/3aa8a265-69a5-49ce-b037-3af09b17d9b8.pdf"
#> [15] "https://api.trigonocapital.com/files/contents/885360b5-b0e7-493a-8555-eedd22b4f8cb.pdf"
#> [16] "https://api.trigonocapital.com/files/contents/2cd86d64-39d2-45a5-91a7-5fb7a6ffd5a2.pdf"
#> [17] "https://api.trigonocapital.com/files/contents/b137a3fc-96f4-49af-bc81-0098c9624f9f.pdf"
#> [18] "https://api.trigonocapital.com/files/contents/c05d95be-206f-484c-acfd-b9f026662279.pdf"
#> [19] "https://api.trigonocapital.com/files/contents/2c06ea17-f841-4ef9-884b-5deb8e1b99ae.pdf"
#> [20] "https://api.trigonocapital.com/files/contents/119cd069-59ff-4c69-9f2c-47f766bf60a4.pdf"
#> [21] "https://api.trigonocapital.com/files/contents/ba8a45d2-5c3d-42b9-ae82-9f147a2f5f0a.pdf"
Perceba que aqui eu estou pegando informações específicas, mas você pode tornar a variável conteudo em um data.frame que vai te ajudar a analisar as informações.
Espero ter ajudado, apesar de fugir bastante do seu jeito. Utilizando de API’s é mais seguro e estável do que lidar com o HTML da página em si.
Abraços