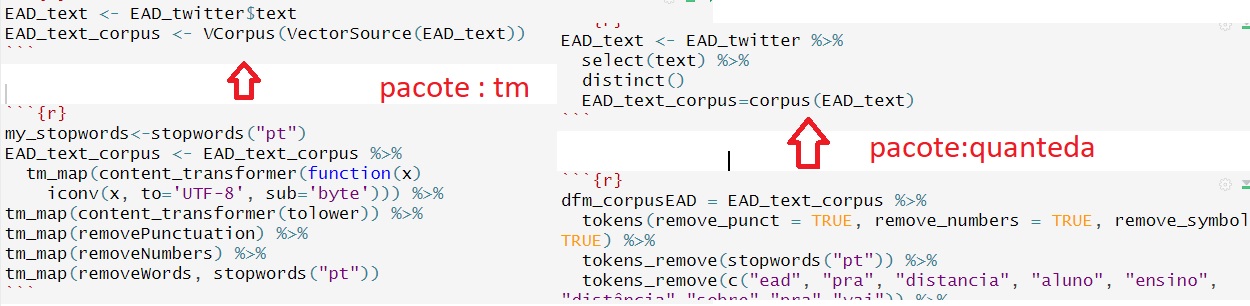
Por favor me ajudem a ver se minha afirmação está correta
minha dúvida não está no código e sim se minha afirmação está correta.
Quando transformo o texto em corpus , usando o (corpus)VectorSource do pacote Tm na hora de fazer a limpeza eu só posso fazer
pelos comandos tm_map.
Agora , quando eu crio um corpus usando o corpus do pacote “quanteda” na hora de limpar eu só posso usar os comando tokens e dfm, nao pode mais os tm_map e vice-versa.
Esta certo?
Também percebo que é mais fácil criar um TermDocumentMatrix no pacote tm, por que não consigo quando estou usando o pacote "quanteda’?
O meu objetivo é pegar um texto transformar num corpus depois em uma matriz para chegar numa nuvem de palavras, qual melhor caminho? tm ou quanteda ?