Rafael,
A lógica do seu código estava perfeita, então, só porque você pediu, vou deixar alguns comentários sobre a forma (e não o conteúdo) do programa:
- Não precisa de uma linha em branco entre cada linha da pipeline. Isso deixa o código muito esparso;
- Só use a notação lambda do
map() para funções de no máximo uma linha, senão fica difícil entender o que está acontecendo;
- Se você vai dar
library(tidyverse), não é necessário invocar as funções com dplyr::;
- Não faça pipelines horizontais como
fundo %>% str_squish(). Uma pipeline serve para encadear manipulações complexas, então nesse caso é melhor fazer str_squish(fundo);
- Ainda no mesmo tema,
names(.) %>% magrittr::extract(1) é equivalente a names(.)[1]. Nem só de tidyverse é feito o R;
- Respeite os alertas e mensagens porque eles dão informações importantes sobre o código. No seu caso, a função
funs() foi deprecada e você não lidou com os “-” das colunas numéricas;
- Atente-se às porcentagens (no caso, a coluna
pl_medio_taxa_de_adm_aa), pois elas precisam ser divididas por 100 quando viram números;
- Seja consistente quanto às aspas, ou seja, use somente aspas duplas ou somente aspas simples e
- Quando não forem necessários, prefira omitir os nomes dos argumentos. Em
str_remove_all(string = ., pattern = "\\_r"), por exemplo, minha sugestão seria o muito mais compacto str_remove_all(., "\\_r").
Aqui vai a minha solução:
# Pacotes necessários
library(rvest)
library(tidyverse)
library(janitor)
# Locale para datas e números em português
brasil <- locale(date_format = "%d/%m/%Y", decimal_mark = ",")
# Função para parsear uma tabela
parse_table <- . %>%
html_table(FALSE) %>%
as_tibble() %>%
mutate(
across(.fns = ~ifelse(row_number() == 2, paste(lag(.x), .x), .x)),
categoria = ifelse(row_number() == 3, lag(X1), NA)
) %>%
row_to_names(2) %>%
rename(fundo = 1, categoria = 14) %>%
set_names(str_remove, "\\(.*?\\)|R[$]") %>%
clean_names(numerals = "middle") %>%
mutate(tipo = ifelse(str_starts(cota, "[A-Z]"), cota, NA)) %>%
fill(tipo, categoria) %>%
replace_na(list(tipo = "Ações")) %>%
mutate(across(.fns = str_squish)) %>%
filter(tipo != cota) %>%
relocate(categoria, tipo) %>%
mutate(
pl_medio_taxa_de_adm_aa = str_remove(pl_medio_taxa_de_adm_aa, "%"),
categoria = ifelse(categoria == "Ações Fundo", "Ações", categoria)
) %>%
type_convert(na = c("-", ""), locale = brasil) %>%
mutate(pl_medio_taxa_de_adm_aa = pl_medio_taxa_de_adm_aa/100)
# Parsear as tabelas
"https://bit.ly/3rrMoPP" %>%
read_html() %>%
xml_find_all("//table") %>%
map_dfr(parse_table) %>%
glimpse(width = 70)
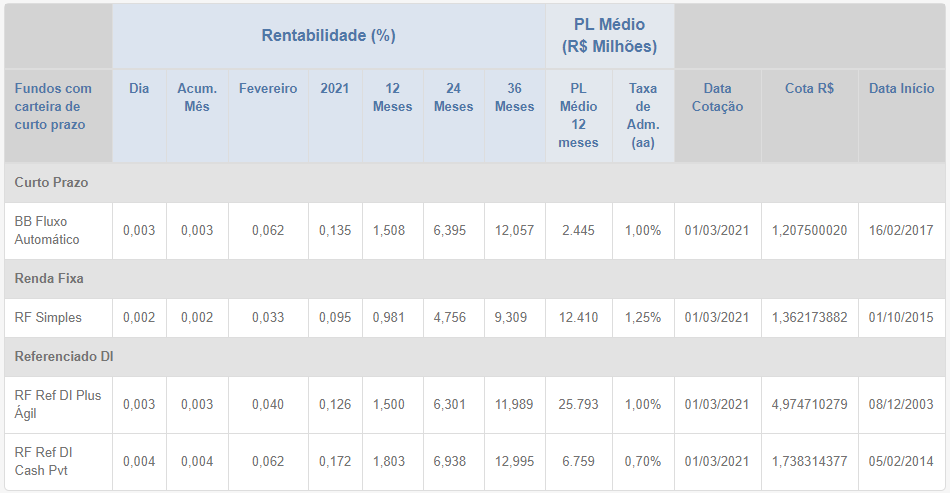
#> Rows: 133
#> Columns: 15
#> $ categoria <chr> "Fundos com carteira de curto pra…
#> $ tipo <chr> "Curto Prazo", "Renda Fixa", "Ref…
#> $ fundo <chr> "BB Fluxo Automático", "RF Simple…
#> $ rentabilidade_dia <dbl> 0.003, 0.003, 0.007, 0.008, 1.439…
#> $ rentabilidade_acum_mes <dbl> 0.014, 0.014, 0.023, 0.028, 2.971…
#> $ rentabilidade_fevereiro <dbl> 0.062, 0.033, 0.040, 0.062, 1.995…
#> $ rentabilidade_2021 <dbl> 0.145, 0.106, 0.146, 0.196, 11.25…
#> $ rentabilidade_12_meses <dbl> 1.347, 0.865, 1.319, 1.622, 25.30…
#> $ rentabilidade_24_meses <dbl> 6.023, 4.438, 5.905, 6.538, 53.95…
#> $ rentabilidade_36_meses <dbl> 11.688, 8.981, 11.593, 12.595, 82…
#> $ pl_medio_pl_medio_12_meses <dbl> 2549, 12889, 26008, 6894, 522, 26…
#> $ pl_medio_taxa_de_adm_aa <dbl> 0.0100, 0.0125, 0.0100, 0.0070, 0…
#> $ data_cotacao <date> 2021-03-04, 2021-03-04, 2021-03-…
#> $ cota <dbl> 1.207624, 1.362333, 4.975702, 1.7…
#> $ data_inicio <date> 2017-02-16, 2015-10-01, 2003-12-…
Created on 2021-03-04 by the reprex package (v1.0.0)

 .
.
 Infelizmente não consigo imaginar o que pode estar acontecendo.
Infelizmente não consigo imaginar o que pode estar acontecendo.